285. BigQuery 省錢大作戰
WHY
又來玩新東西了,這次是BigQuery。
Note
BigQuery的費用計算方式,儲存空間+分析。
- BigQuery 採用資料欄式資料結構。系統會根據您所選資料欄中處理的資料總量向您收費,每個資料欄中的資料總量則是按照資料欄中資料的類型計算。如要進一步瞭解資料量的計算方式,請參閱估算查詢費用一節。
- 您只需支付查詢共用資料的費用。資料擁有者不會在資料存取時收費
- 如果查詢作業傳回錯誤訊息或是從快取中擷取結果,則您不必付費。 以 程序語言工作來說,系統會在個別陳述式層級採用這個計價模式。
- 資料量會四捨五入至最接近的 MB 數。針對查詢所參照的每個資料表,系統處理的資料量基本額度為 10 MB,每項查詢作業處理的資料量基本額度也同樣是 10 MB。
- 即便您取消正在執行的查詢工作,該項作業還是可能產生費用,且價格最高等同於完整執行作業須支付的全額費用。
- 當您執行查詢時,系統會根據您所選資料欄中處理的資料量向您收費,即使您已明確對結果設定
LIMIT也是如此。 - 將資料表分區和分群有助於降低查詢處理的資料量。為達到最佳做法的成效,請盡可能採用分區和分群的做法。
- 以量計價 (每 TiB) 的定價是指 Google Cloud SKU 頁面上的分析價格。
- 如果您對叢集資料表執行查詢,而且查詢含有叢集資料欄篩選器,則 BigQuery 會使用篩選器運算式來修剪查詢掃描的區塊。這麼做可以減少掃描的位元組數。
ref. 以量計價的運算價格
注意事項
- 避免反覆覆蓋表: 系統會在時間旅行和故障安全窗口期間保留被替換的資料。如果您經常覆蓋表,則會產生額外的儲存空間費用。
- 使用下列方式探索或預覽資料
- 在 Google Cloud 控制台的資料表詳細資料頁面中,按一下「Preview」(預覽) 分頁標籤,即可取樣資料。
- 在 bq 指令列工具中,使用
bq head指令並指定要預覽的資料列數。 - 在 API 中,使用
tabledata.list從一組指定的資料列擷取資料表資料。 - 請避免在非叢集資料表中使用
LIMIT。如果是未經叢集的資料表,LIMIT子句不會降低運算費用。
- 建立叢集資料表:在每個修改資料表的作業中,叢集資料表都會保留其排序屬性。依叢集化資料欄篩選或匯總的查詢,只會根據叢集化資料欄掃描相關區塊,而不會掃描整個資料表或資料表分區。感覺上像是index
- 使用分區將大型資料表分割:分區資料表劃分為多個區段 (稱為分區),可讓您更容易管理和查詢資料。將大型資料表分成較小的分區,可以提高查詢效能,並且可以透過減少查詢讀取的位元組數來控制費用。
- 使用長期儲存價格,降低舊資料的費用:超過90天沒用過的資料,會降低50%的金額儲存空間定價。
- 為目的地資料表使用資料表到期時間:如果您將大型查詢結果寫入目的地資料表,請使用預設資料表到期時間,等到您不再需要這些資料時,系統便會依照設定的時間來刪除資料
- 寫入資料方式:批次不用錢,串流需要。
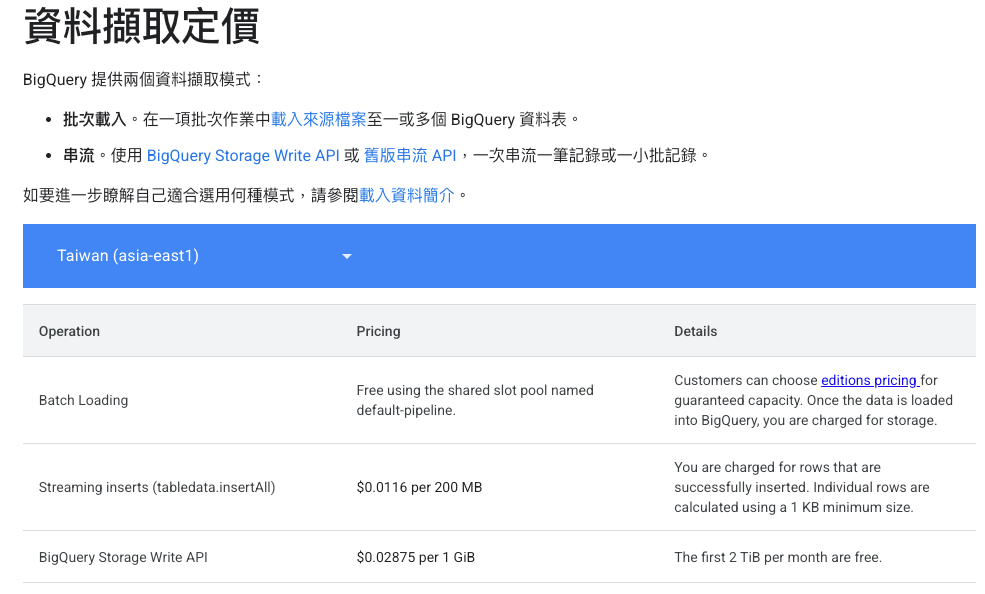
選擇哪一種方式,參考下圖
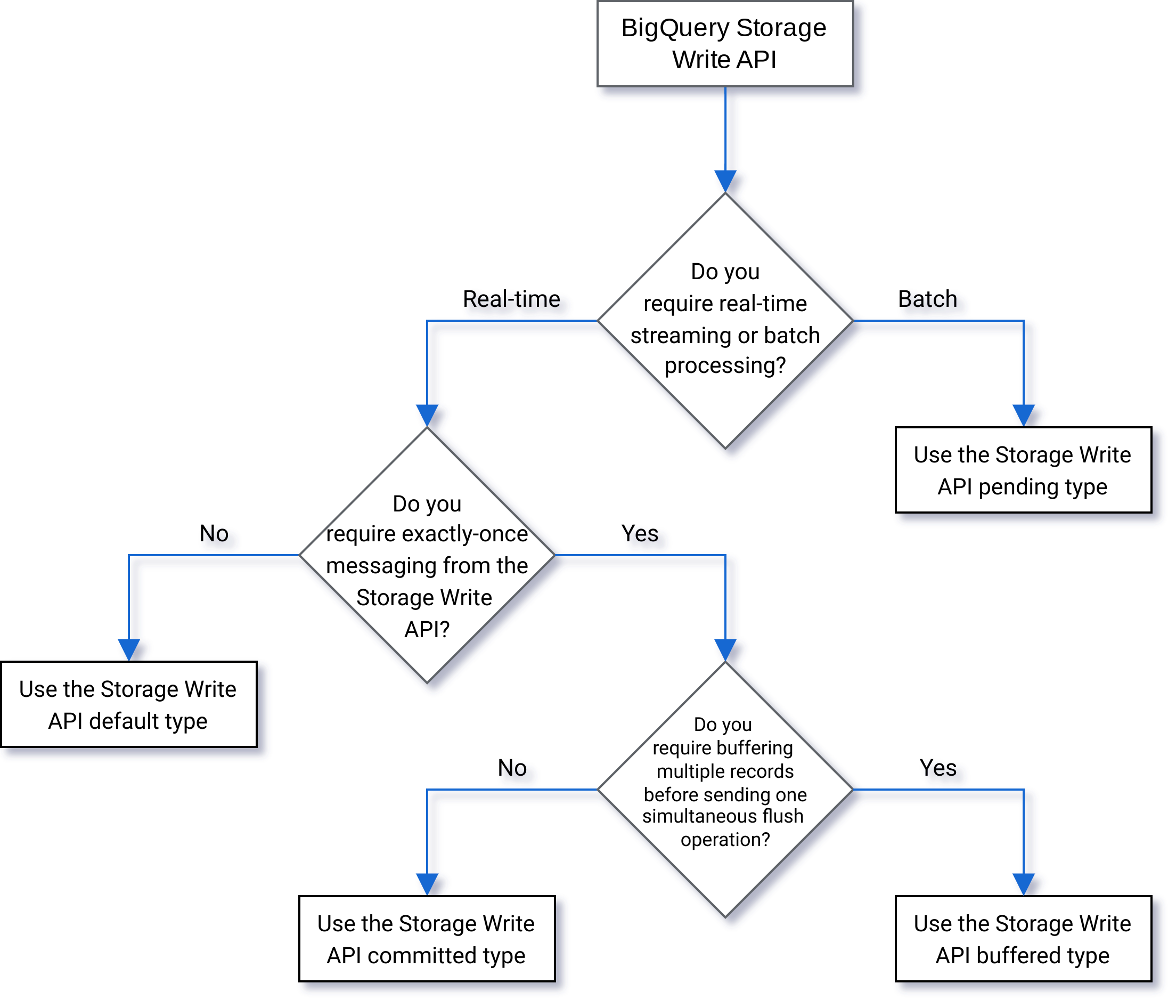
ref. BigQuery Storage Write API